
How to Learn Machine Learning Online: Step-by-Step Beginner’s Guide
To learn machine learning is no longer confined only to data scientists or researchers. Anyone can learn machine learning. If you have a passion to learn, then anyone can learn it with a structured plan or roadmap.
Today machine learning is a fundamental skill like MS Word or Excel we learned in 2000–2001. If you are a developer, analyst, project manager, or a college student-learning ML can open multiple opportunities for you, and you will also gain an understanding of how modern technology works behind the scene.
Today many learners have 2 main questions in their mind:
• How can you learn ML online in an effective way?
• What is the list of things that work or do not work?
In this blog I will share all the steps in a detailed way—how I learned Machine Learning from zero knowledge to working with big tech companies and contributing to real-time ML projects. I will also share points—how I stayed consistent, what mistakes I had made in my learning periods and how I corrected my mistakes so that you can take from my experience. Please note that this is not a course syllabus. In fact, it is a real guide based on my personal professional experience.
Why Learning Machine Learning Online in 2025 Works Better Than Ever!
Sixteen years back when I heard about machine learning for the first time, at that time I thought I needed a master’s degree from a top university. But that was an incorrect opinion.
Today if you want to make a successful career in this field, then:
• You need the right guidance to learn ML.
• You can train your ML models with freely available datasets.
• You can learn from notebooks like Google Colab.
• You can also join multiple ML communities and gain knowledge.
The most important point is: You should always learn machine learning by building. That will help you build confidence and you will be able to contribute to real-time ML projects more effectively. I also used the same approach during my learning journey.
How I Started: Confused and Exhausted
In 2009, I started learning AI by watching multiple YouTube videos. I also purchased 5+ ML books as well on top of that. I also joined multiple online groups, but these multiple sources added more confusion and nothing worked out for me. At that time, I was trying very hard to learn ML but I was not putting my efforts in the right direction.
After 6 months of wasting time, I sat and listed down all the things that I was doing and corrected my mistakes. I planned and wrote down a six-month journey that was mainly focused on 3 important points:
• At the start, you don’t need to master everything.
• Once you start working on real-time projects, then you will face problems that will give you an opportunity to learn in a deeper way.
• After building, you should share your learning with others (mentors/friends) and take serious feedback and improve from there onwards. This type of mindset helps you grow at a fast pace.
The Learning Journey: Month-by-Month Detail
Month 1: Focused Only on One Thing at a Time-Writing Python Code Only
This means I didn’t try to learn multiple things at a time. I didn’t jump directly to learn machine learning. I picked only one skill at a time-Python and I practiced every day.
Because code is written in every ML-based project, so:
• I spent 2 hours on a daily basis and started by writing small programs.
• I remember I made 90+ errors in the first week and started Googling to correct my mistakes... but the main point was, I was debugging on a regular basis and it helped me to build problem-solving skills.
• By day 20, I started working on a mini-Python-based project.
Please remember that my goal was not to become a Python expert, but I wanted to feel comfortable enough to write, read, and modify Python code with confidence.
At the End of the First Month:
• I was able to understand what existing Python code was doing.
• I was comfortable modifying the code based on project needs.
• I was able to write basic functions and logic at a fast speed.
For the complete Python syllabus, please refer to the syllabus mentioned in Machine Learning Course. 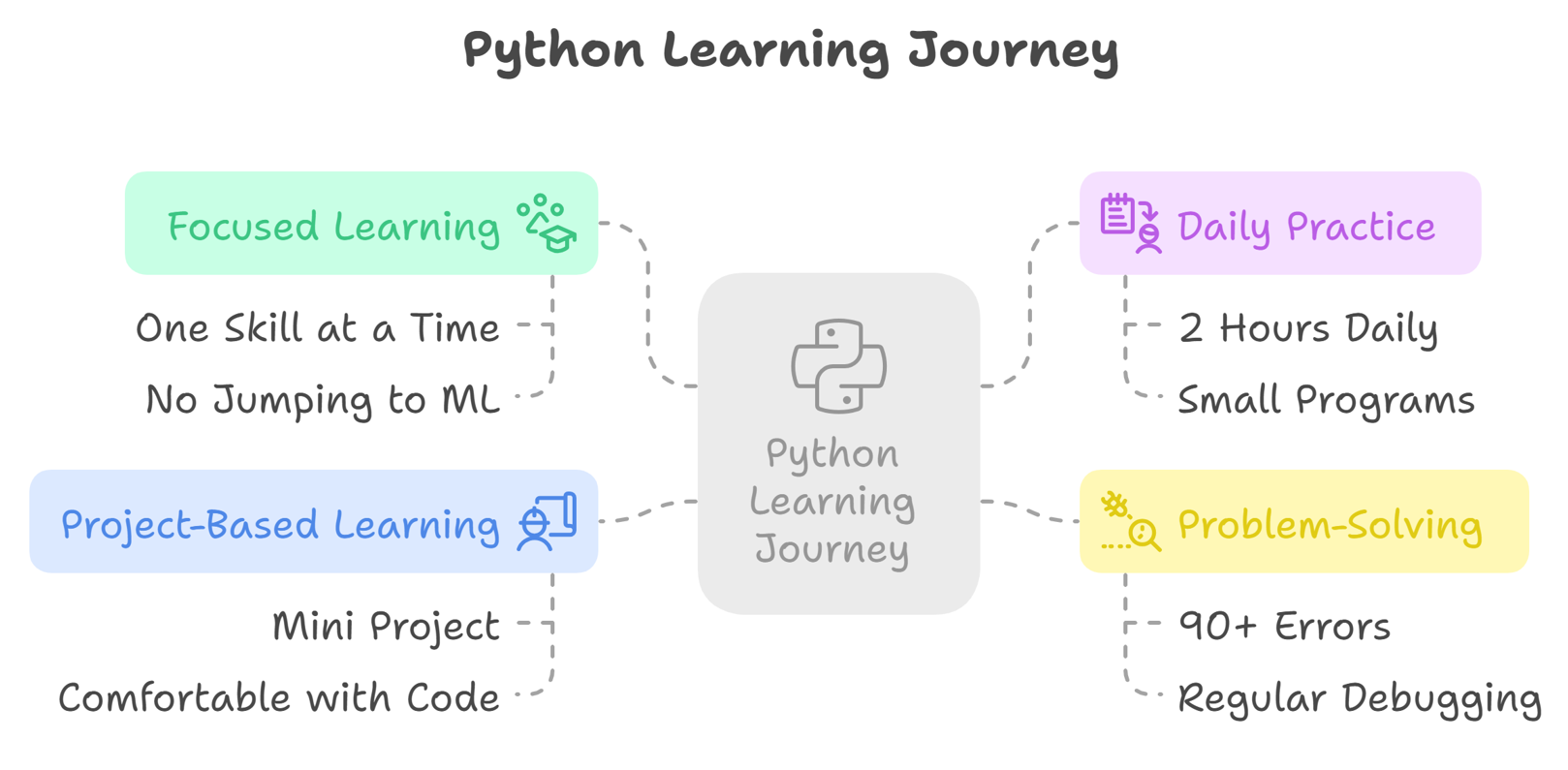
Month 2: I Faced My Fear – The Math Behind ML
I tried to avoid math for years and also avoided solving math equations because I felt these things had no practical usage in real life. But after some time, I got clarity that if I want to make a successful career in ML, then I should not avoid math.
So, I had to find a new practical approach—and luckily, following these things worked for me:
I stopped cramming formulas and started simulating them with the help of the Python language.
Instead of cramming formulas like:
Y = mx + b
Gradient = d/dx
I started writing Python code that basically helped me to use Python practically. For example:
• I created a list of values for x and y.
• Then I calculated the line that best fit in a manual way.
• After that, I plotted visually how the line changed as we changed the slope of the line (m) and intercept (b).
With this approach, I didn’t memorize formulas - I could see them working in front of my eyes.
I Created a Python Script That Showed How Linear Regression Finds the Best Fit Line for Prediction.
In this step, I followed multiple things:
• I generated random data points using the NumPy library.
• I coded a function in Python and tried multiple values for slope and intercept.
• I also used a Python loop so that error could be minimized between actual and predicted points.
• I also plotted the result using the Matplotlib library.
After that, I compared it with Scikit-learn and in that way, I was successfully able to build my first linear regression from scratch. This small project helped me to understand the regression concept in a better way. It was not just a formula for me anymore—but it was a real and visual thing that helped me to gain confidence.
I Visualized Gradients with Matplotlib Library.
Initially, I was afraid of words like partial derivatives and cost function, and at that time I had zero idea about gradient descent. But I followed two important steps:
• I defined a loss function in Python and plotted it using the Matplotlib library.
• After that I calculated the slope at different points and added arrows to see how the gradient leads you toward the minimum.
This approach helped me understand optimization without reading any calculus book. That day, I understood how models tune themselves to perform better.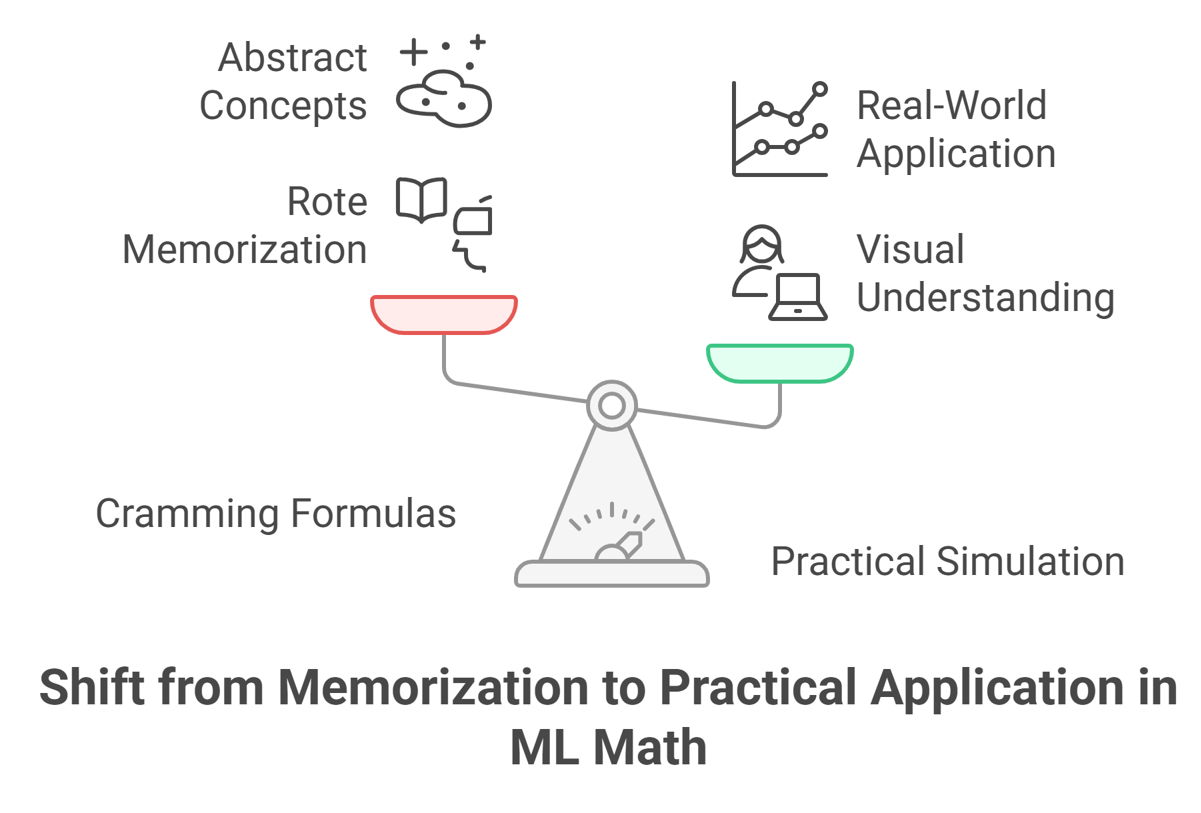
Key Takeaway:
You don’t need to study math, but you should learn to use it. In this way, you will start taking interest - and will always remember it.
Month 3: I Built My First Real ML Model (And Failed First!)
By this time, I had put enough practice of coding using Python language and understood important concepts of maths as well. So, I decided to take a project – ‘Loan Default Prediction’. This is a classic ML problem where the objective is to predict whether a loan applicant will default or repay that loan. And again, I used a dataset with borrower information like income, age, credit score, loan amount, loan type, and repayment status. My objective was to train an ML model using this dataset.
I was happy and excited, as I found that my model had 86% accuracy on predictions of whether people repay their loan or not.
I learned a very big concept here. At that point, I didn't know that you can’t evaluate your model using imbalanced data. I had no idea about the meaning of imbalanced data.
But I didn't give up and started using a new approach. I broke down the huge problem into a smaller one and started working on fixing one thing at a time.
So, I performed three steps:
• Cleaned the dataset (handled missing values, duplicates, and also dropped irrelevant fields).
• Split training and test data correctly.
I used train_test_split() to create a 70:30 split. After this data split, my accuracy dropped significantly, but now the metrics were correct and realistic.
• Used a Confusion Matrix. It tells if our model is making good predictions or common mistakes.
As the data was so imbalanced, I went for a better metric to measure performance.
The confusion matrix helped me to find:
• How many defaulters my model was actually catching.
• How many non-defaulters it wrongly predicted as defaulters.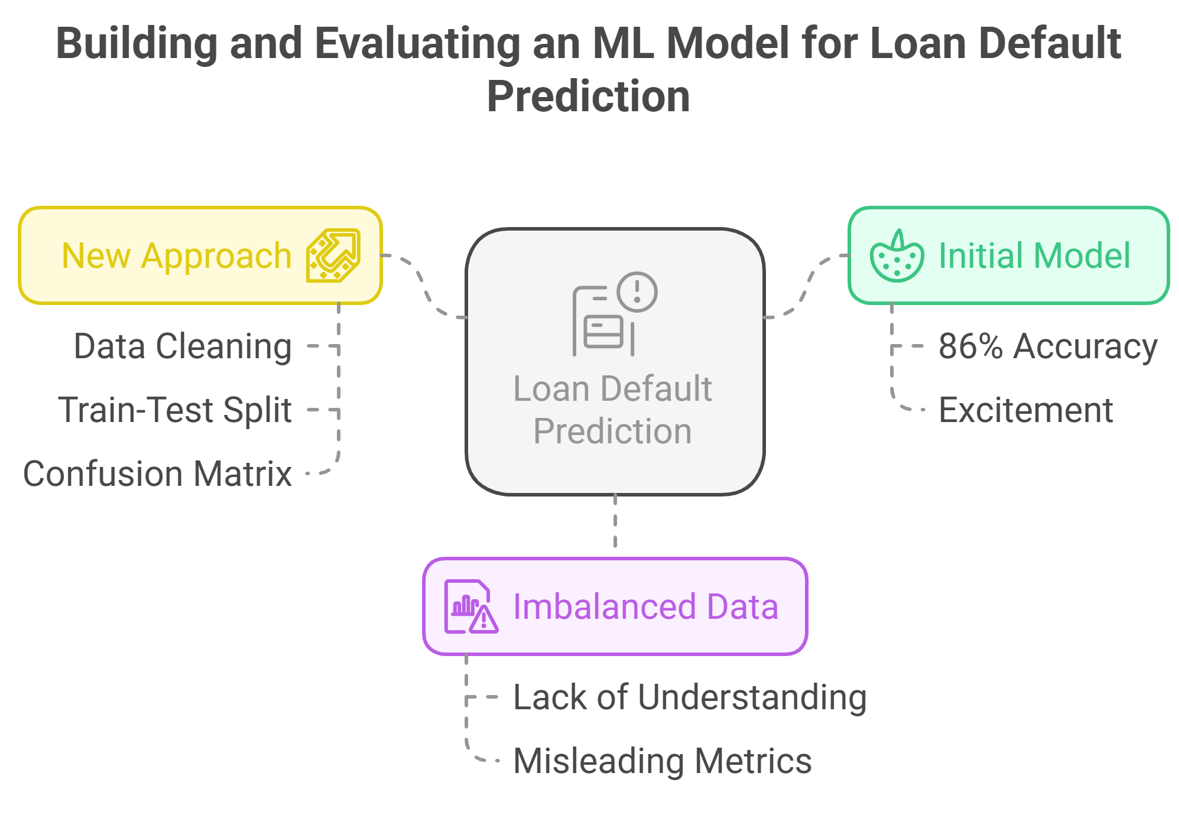
Key Takeaway:
At this month, I understood an important lesson — You don't need to learn everything before start time. Once you start working, try learning by solving real problems. This way, you can improve in a better way.
Month 4: Power of Feature Engineering
It means transforming data into useful information so an ML model can learn better. Most people think that an ML model’s performance will be good if we use complex algorithms like random forest or deep learning. But I can tell you confidently that if you have clean and structured data, then even a basic model can perform exceptionally well. That is where I came to know about feature engineering.
Let us try to understand with the help of an example.
I had a dataset with customer age ranging from 17 to 65. So, initially, I used age as a raw numeric feature. The model didn't seem to learn much from this data. After this, I tried to bucket the age into groups like:
• 17–25: Young Adults
• 26–40: Working Professionals
• 41–60: Seniors
• 61+: Retired
Suddenly, the ML model picked this pattern and started matching age.
Default risk was higher in the 17–25 group. Loan approvals were more likely in the 26–40 group.
It helped me to understand an important lesson: Preparation of data is far more important than model optimization.
Key Takeaway:
One should spend more time on improving the quality of your data than tuning the parameters of a model. So, I started thinking like a Data Scientist (not like a Python Developer).
Always remember that 70% of total time should be spent in cleaning, organizing & preparing data and the rest 30% of time should be spent on modeling & evaluation.
Month 5: I Built Projects That I Could Show on GitHub
Till now, I was building useful end-to-end ML projects that I could share with others to showcase my capabilities. So, I started working on these 2 real ML projects:
Customer Churn Predictor
ML model to predict whether a customer will cancel a subscription or not. I used the telco data to train my model:
• Plan type
• Payment history
• Total usage time
• Login history
• No. of support calls
In this project, firstly I cleaned the customer data using pandas and sklearn, then used a random forest model to train on historical churn (Yes/No). Finally, I built a dashboard using streamlit where you can enter customer details and you can get prediction — Yes or No.
Note: Big telecom companies or Netflix use this type of model to retain customers before they leave.
House Price Predictor
It predicts the selling price of a house based on input data like location, size, and amenities.
Firstly, I collected the housing prices dataset from Kaggle (www.kaggle.com). This dataset had multiple features like:
• Square footage
• No. of bedrooms and bathrooms
• Location
• Year built
• Balcony
• Garden area count
Then, I performed removal actions and handled missing values. In the next step, I created new features like:
• Age of house
• Price per square foot
Finally, I experimented with multiple models and selected the Random Forest model due to its strong performance. I also tuned the Random Forest model using GridSearchCV to find the right parameters. At the end, I built a streamlit web app in which you can input:
• Location
• Bedrooms
• Size
• Year built
And can see the instant result (like predicted price).
This project helped me to learn the end-to-end ML lifecycle - How ML models work and when they fail.
Note: Real estate websites like MagicBricks and housing apps use this type of model for property valuation.
The important part is:
I shared both projects on GitHub with
• A README file (like an instruction manual for the project)
• Sample data and screenshots of the app

Key Takeaway:
Don’t go after certifications. A well-documented GitHub repository speaks louder than experience in the tech industry.
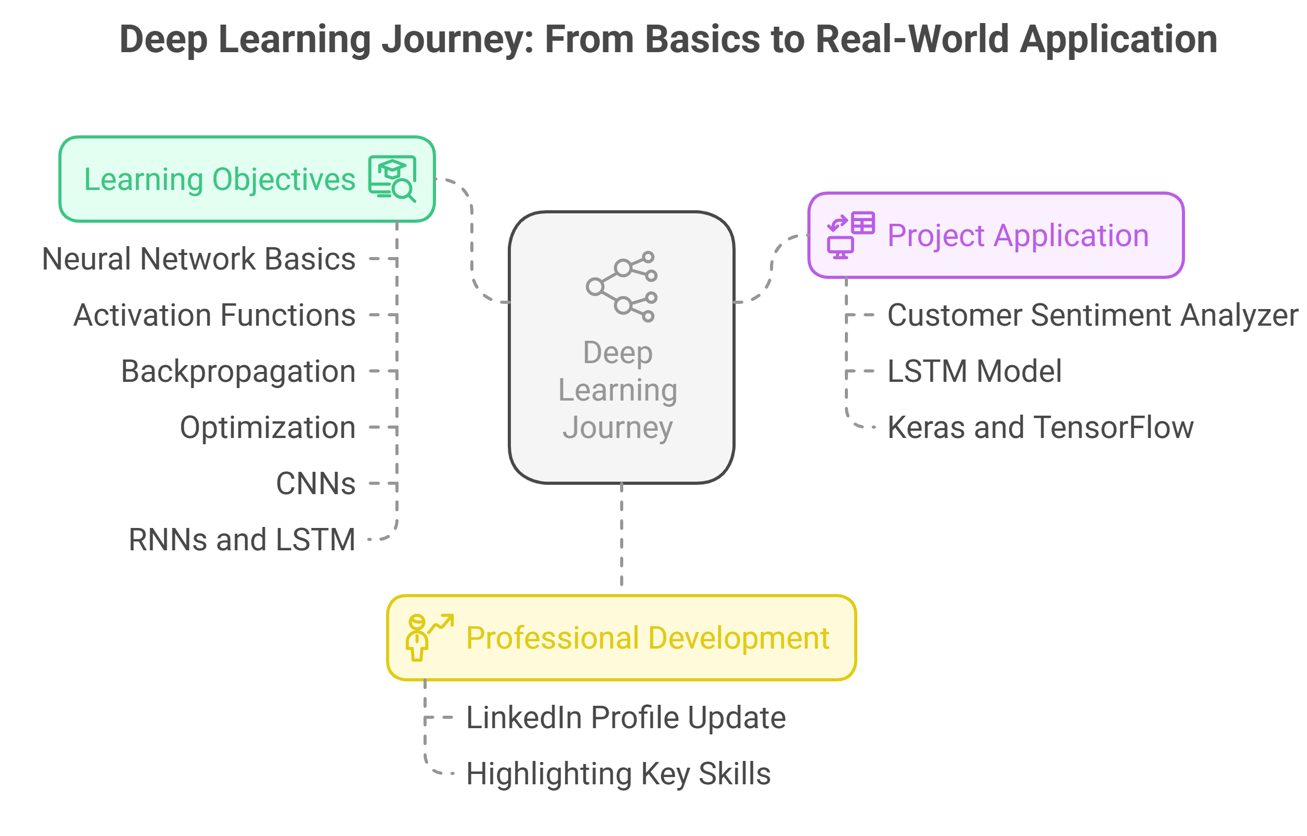
Month 6: I Tasted Deep Learning and Prepared for Real Jobs
Till now I had gained confidence in ML as I had made 2 real-life projects. In this month, I wanted to learn the technology behind several real use cases like self-driving cars, chatbots, facial recognition etc.
Please note, at this time, I didn’t want to dive deep into DL. Instead, my focus was to understand the basics so that I could write business value-adding projects in this area/field.
I learned a few important DL topics like:
• Neural Network basics
• Activation functions (like ReLU, Sigmoid etc.)
• Backpropagation
• Optimization
• Convolutional Neural Networks (CNNs)
• Recurrent Neural Networks and LSTM
At the end, I worked on a project: Customer Sentiment Analyzer
It predicts if a customer is happy or not based on product reviews. The model for this project used a Deep Learning (DL) model called an LSTM (Long Short Term Memory), and this model is good at understanding text.
This project helped me to understand how:
• Backpropagation updates weights and improves the model performance in future rounds.
• If a model does not adapt predictions, then you backtrack and adjust its weights.
I used Keras and TensorFlow libraries for building and training our neural network model.
At the end, I also updated my LinkedIn profile and highlighted three important things:
• Problem statement
• Approach I used to solve it
• Outcome
I also mentioned my use of deep learning, NLP, and deployment.
Key Takeaway:
Please remember that your first job will come from visibility, so always share your knowledge on social media platforms and network with like minded people. Your technical knowledge is your potential, but if you share it, then it becomes a power.
Things That Helped Me Stay Consistent
• I promised myself that I would study 2 hours on weekdays and 3–4 hours on weekends.
• I made a diary and noted down (at night time) what new thing I had learned today.
• I celebrated my small achievements like cleaning a dataset, improving the model accuracy, or deploying an ML model.
• These habits helped me stay motivated during my learning period.
Projects That Made a Difference in My Learning
Building projects during the learning period played an important role in enhancing my skills. Not only did it help me enhance my technical skill (in the AI field) but also gave me an opportunity to solve real-world problems.
Customer Churn Predictor:
The objective of this project was to find out the list of customers who are about to leave/stop using a service. And this project helped me to understand how big telecom companies use ML technology to retain customers for the long term.
I followed 4 steps:
• Firstly, I collected, cleaned, and explored customer data (with features like tenure, charges, contract type etc.)
• Then, I built a classification model so that it could predict "churn" (using binary classification)
• In the third step, I added clear visualizations to display the most important features (like contract type, customer tenure, or monthly charges). These visuals made the business manager's job easy to understand the real reason why customers are churning so he can act and re-target them by offering better plans at cheaper prices etc.
• Finally, I created a simple web application using the Streamlit tool and kept the UI simple and user-friendly. This helped to make the project interactively interesting.
It helped others to see and test the model and show real potential.
Customer Sentiment Analyzer:
It was a DL project where I trained a model so that it could understand the emotions expressed in the online comments section. I used NLP techniques and an "attention" approach to make it insightful!
• To classify the sentiment.
• To highlight keywords and phrases.
I used the following approach:
• I cleaned the data/text by removing unnecessary/unwanted things (like capital letters and punctuation marks).
• I broke down the sentence into small parts (called tokens) and converted them to numbers so that a model could understand it.
• Finally, I used an LSTM model so that it could understand the order and meaning of words in customer reviews in a better way.
• Finally, I added a way to see results which would highlight words receiving the most attention, and this helped to understand why the model predicted a certain result.
It helped business in many ways:
• Businesses can get real feedback on product/service in a fast way.
• It helps to identify real pain points of customers.
• It helps to understand customer emotions automatically and saves manual review time.
House Price Predictor:
The goal of this project was to predict house price based on features like:
• Location
• Size
• No. of rooms/bathrooms
• Year the house was built
For this project, I followed a steps approach:
• Firstly, I collected and cleaned housing data (like handling missing values and converting text fields to numeric etc.)
• Then, I used charts to find patterns
• I used multiple models (given below) to predict the amount and evaluated performance using RMSE (Root Mean Squared Error):
o Linear Regression
o Random Forest
o XGBoost
• After comparison, I selected the Random Forest model.
• Using Streamlit, I built an interface where end users can enter information and based on that, they can get the expected output in the form of a house price.
• Finally, I uploaded the complete project on GitHub with a working demo site so that others could try it.
Benefits:
• It saves a lot of time, as the model gives instant price estimates.
• It is easy to scale this model in different cities or property types with new data. 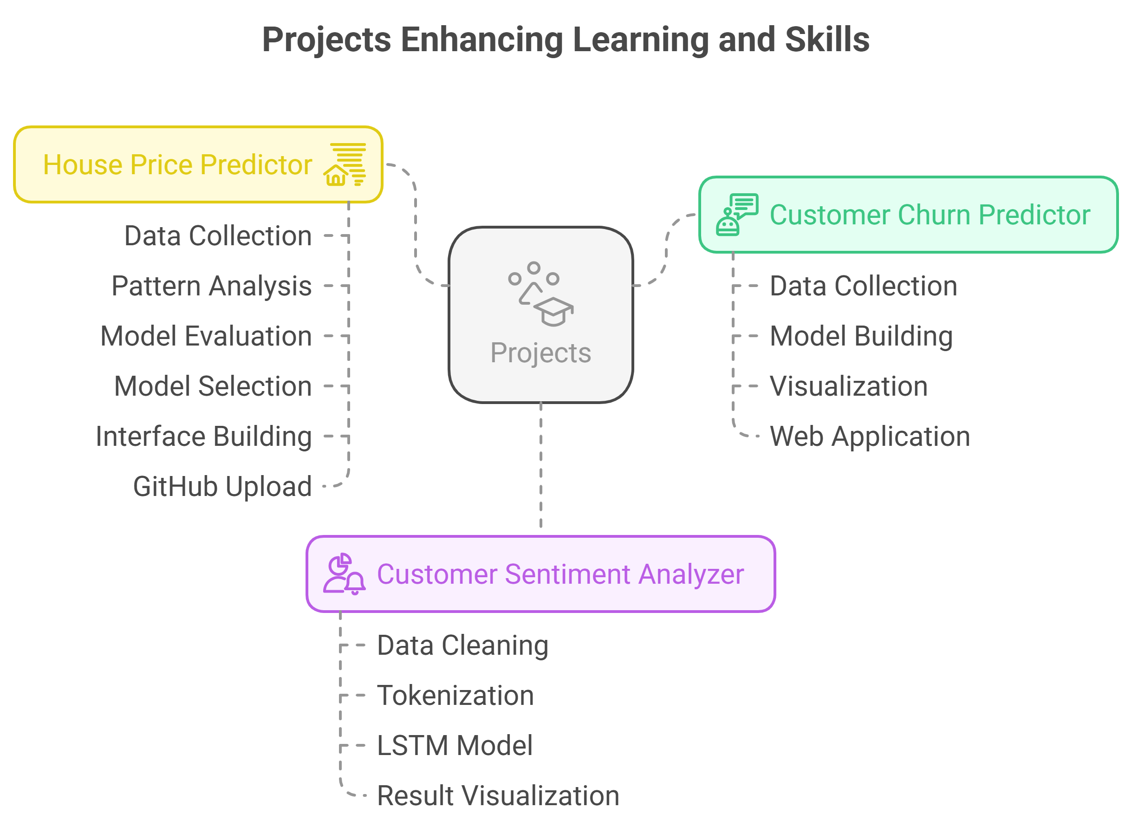
List of Challenges and How I Solved Them:
Lack of Structure:
In the first few months, I had no clarity on which topic I should cover first, and there was no order for me.
Solution: I planned and wrote a month-wise roadmap and I focused on one skill at a time (first Python, then Math, and finally ML). It helped me a lot.
Doubting Myself:
I often used to compare myself to others and started doubting myself.
Solution: I made a habit of studying at least 2 hours a day and this gave me confidence.
Tutorial Fatigue:
I watched so many videos, blogs, and at the end, I felt I had learned nothing and confused myself.
Solution: I started building real projects. I did not copy code, instead, I wrote my own versions of the code to solve problems.
No Mentor:
I felt isolated, as I didn't have any mentor.
Solution: I connected with my seniors and like-minded people and shared my progress on a regular basis. I asked my questions, and in this way, I learned from others.
Project Paralysis:
Initially, I was afraid to start projects because I thought they had to be 100% correct, so I kept delaying projects.
Solution: I picked a simple dataset and started working on a basic-level project and improved it over time (by working on feedback).
Please note that hard projects teach you more than simple projects.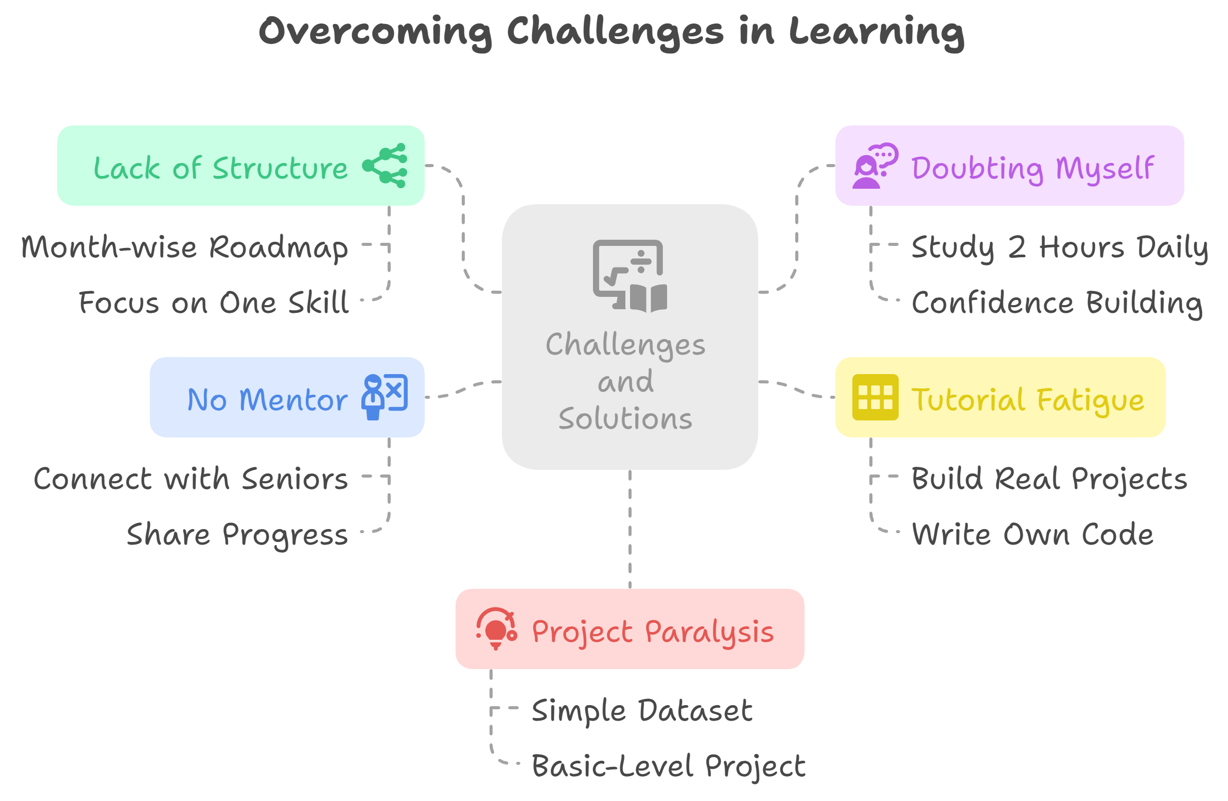
How to Showcase Your ML Skills Online
GitHub Profile:
You should organize your projects on GitHub and also add a README file which contains the following points –
• Description of the project
• Mention all tools or libraries you have used in this project
• How a person can run it on their system
Most of the time, big company recruiters prefer checking candidates’ GitHub to see the quality of code.
LinkedIn Presence:
You should post twice a week (at least) and each post should mention the following things:
• Project details you are working on
• Mention your understanding & your contribution
• What lessons have you learned so far from mistakes?
If you post on a regular basis, recruiters will start noticing you.
Write Mini Blogs:
You should start writing short and simple posts in which you can explain ML topics.
Few examples are:
• What is data leakage?
• What is a confusion matrix and why do we split data into train/test data?
If you explain these small topics in your own words, it will show your deep understanding. In this way, you will also help others, which will make your credibility strong.
Contribute to Discussions:
You can also join forums like Reddit, Kaggle, or Discord where people ask questions. Try to share answers to basic questions and also share your experience as well.
Please remember that you will understand more strongly if you teach others. It will also help you to network with like-minded people.
Portfolio Page:
You can make a simple one-page website and showcase all your work. You can include the following sections –
• A short introduction section
• Mention all the project details with GitHub links
• Paste a few screenshots of all projects
• Also mention content from your LinkedIn links as well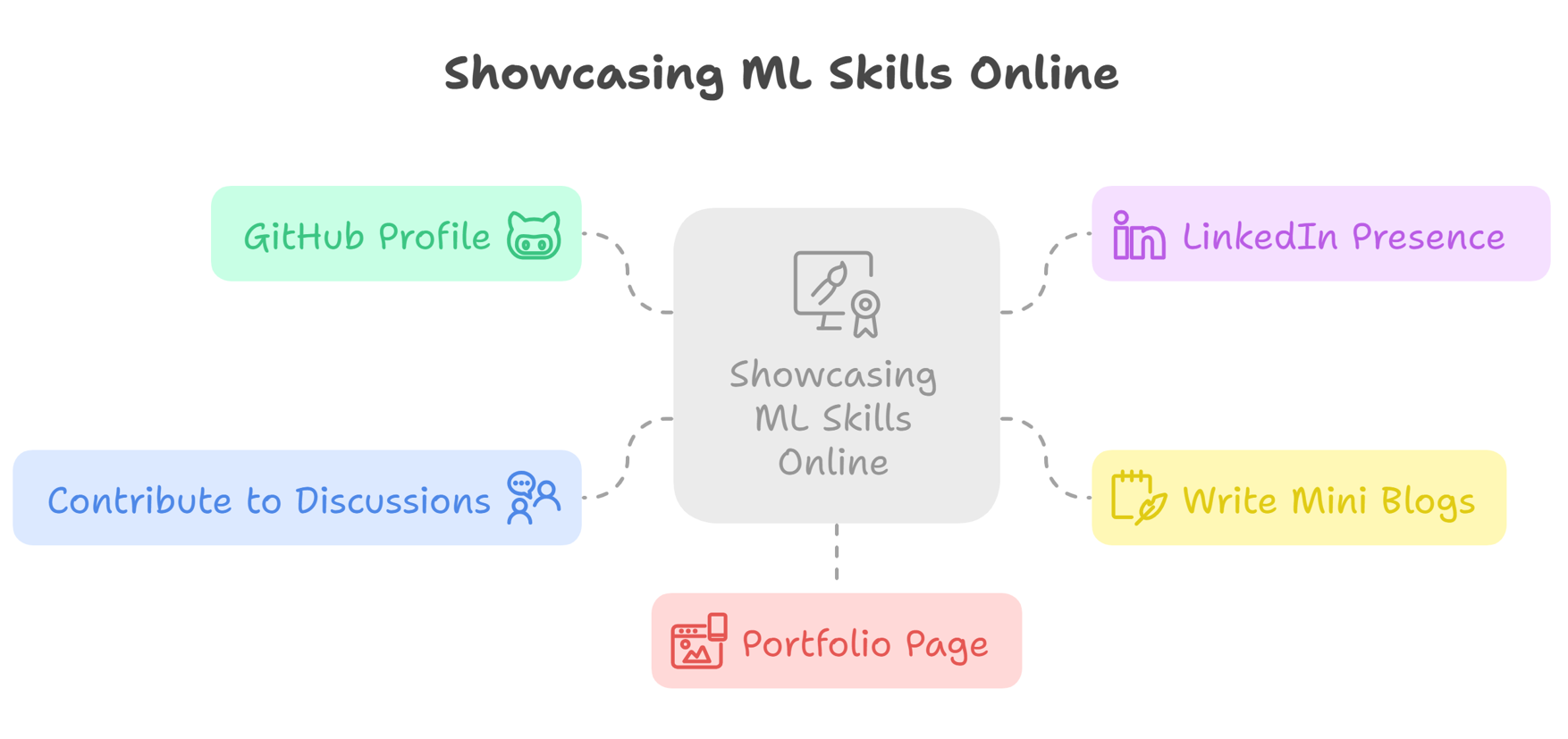
Will This Help You Land a Job or Freelance Client?
Yes, it will if you build your skills and share them on a regular basis.
I know people who –
• Got Data Analyst jobs with zero experience.
• Started earning money as freelancers. They solved real problems and consistently shared their results/achievements. This helped clients gain confidence in a candidate’s ability/skills.
• Started a YouTube channel from their learning journey, honestly and consistently made content, and today, they are earning a good amount of money.
Important Note:
In the beginning, keep your focus on a few important skills and excel in those areas. Don’t try to learn everything at once.
Closing Thoughts: What I’d Do Differently If I Started Again
If I had to start again, then I would do the following things –
• I wouldn’t work on multiple projects at a time, rather I would focus only on one project.
• I would start talking with new people like mentors or friends and would seek their feedback and inputs.
• I would start working on real-life projects rather than just learning theory. It would help me understand, build confidence, and make my understanding stronger.
• I would showcase my work online on a consistent basis, that would help me network with people and get recruiters’ attention.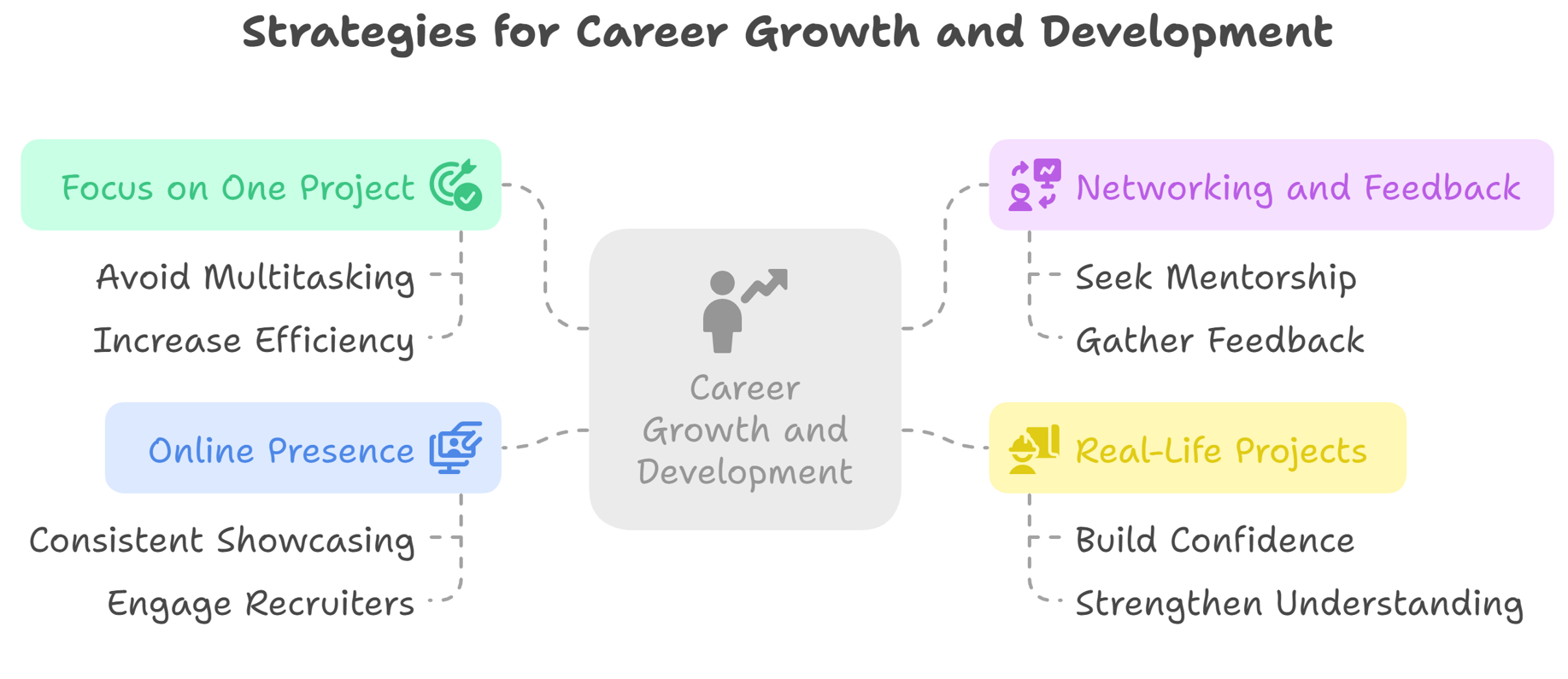
Conclusion
Today learning machine learning online is not only possible – but it will help you to earn a great amount of potential for your family and you can secure your future as well. I still recall, when I started my career 16 years back, I didn’t have any computers degree and I had no knowledge about Jupyter Notebook. In fact, I wasn’t aware of how to load a dataset. I made multiple mistakes, I struggled, but I stayed consistent and this one thing made the big difference.
To get success, you only need 4 steps:
• Search for the best institute that can help you get started in your learning journey and can guide you to get a good ML job.
• You need patience to keep going especially when you are confused or demotivated.
• You need discipline to work hard on a consistent basis and start solving real problems and share them with others.
If you follow this beginner-friendly ML roadmap and give 2–4 hrs daily for the next 6 months, then:
• You will develop a portfolio of projects.
• You will be ready to apply for high-paying jobs or can start your own business as well.
• You will gain the confidence to call yourself an ML practitioner.
Always remember - Consistency is the key to success (not speed).
Frequently Asked Questions (FAQs)
1. Mention the best way to learn ML online in 2025
Ans: I would recommend following a structured project-based approach. Start with Python and build a solid foundation. After that, build and apply ML models gradually.
2. Do I need a Master’s degree to learn ML?
Ans: There is no need for any Master’s degree. If you are ready to put in 2 hours on a daily basis for the next 5–6 months, then you can get a good job.
3. How much time will it take to learn ML?
Ans: It would depend on your efforts, but normally it will take 4–6 months to learn ML.
4. What is the best way to showcase your projects to recruiters?
Ans:
• Start posting blogs on LinkedIn regularly.
• Create a one-page website and showcase your all project details and how you contributed to those projects.
• Upload all your project details on GitHub in a structured way.

