
How to Scale Databases with High Availability Patterns in AWS Cloud
When you build an application on the cloud, the most important layer is the database layer, which plays a critical role in the application's overall performance. This database layer can hold many types of data like transaction logs, business data and customer records. The main challenge comes when hundreds of thousand of users access the application at same time. Based on my experience I have practically seen that in such cases most of the time database goes down due to high incoming traffic. In such scenarios, scalability and high availability plays a very important role.
Scalability means database should be able to handle increased incoming traffic and high data volume. On the other side, high availability means your application (like Amazon or Flipkart) should run smoothly even if something goes wrong behind the scene.
In this blog we will discuss few patterns to scale databases and improve data availability using AWS cloud.
Vertical vs Horizontal Scaling
a) Vertical Scaling:
In this, you increase the size of an existing database instance with more large resources like CPU and Memory so that it could handle large incoming traffic. Please note that if you are hitting performance limits then vertical scaling is quick and easy simple solution. On the other side, vertical scaling has limitations as well as you might hit the maximum available instance size that a cloud provider (AWS) can offer.
Benefits:
• It is easy to manage and implement.
• It is good for small or medium applications.
• It offers better performance when traffic is low.
b) Horizontal Scaling:
In this you add more database nodes that helps you distribute workload and achieve zero-down time scaling. Horizontal scaling helps the system to be more resilient to failures and can be scaled quickly. Also, these types of applications are easy to maintain.
If one database node fails to work, then other nodes continue to work. In this way, horizontal scaling helps to distribute workloads across multiple nodes.
There are two famous techniques used in this – sharding and partitioning. Both of these are used for distributed storage and processing of complete data.
It also has support for zero down time scaling. During peak times, three tasks are performed:
1. Spin up more nodes.
2. Distribute the traffic among these nodes using load balancer.
3. Scale back old ones when traffic decreases.
Benefits
• It is good for large applications to handle millions of reads & write requests.
• It provides high availability.
• Application is globally accessible because data is served from nearest location.
Read Replicas for Better Speed
This pattern is used only if your app gets a lot of read requests from users. In this pattern, you create copies of primary database and each copy handles only read requests and primary database handles writing requests.
Let’s take an example:
There is an e-commerce website which uses Amazon Aurora database service at the backend. On Black Friday sale day, there are millions of users across the globe visiting product pages to see details. To handle this, you can create two or more Aurora read replicas and transfer all read requests to them. This pattern also helps primary database to handle write requests efficiently.
To distribute the traffic, one can use a load balancer. You can also write routing logic in your application. This would help website to run smoothly during peak hours.
This pattern is used when your application receives more read requests than write ones.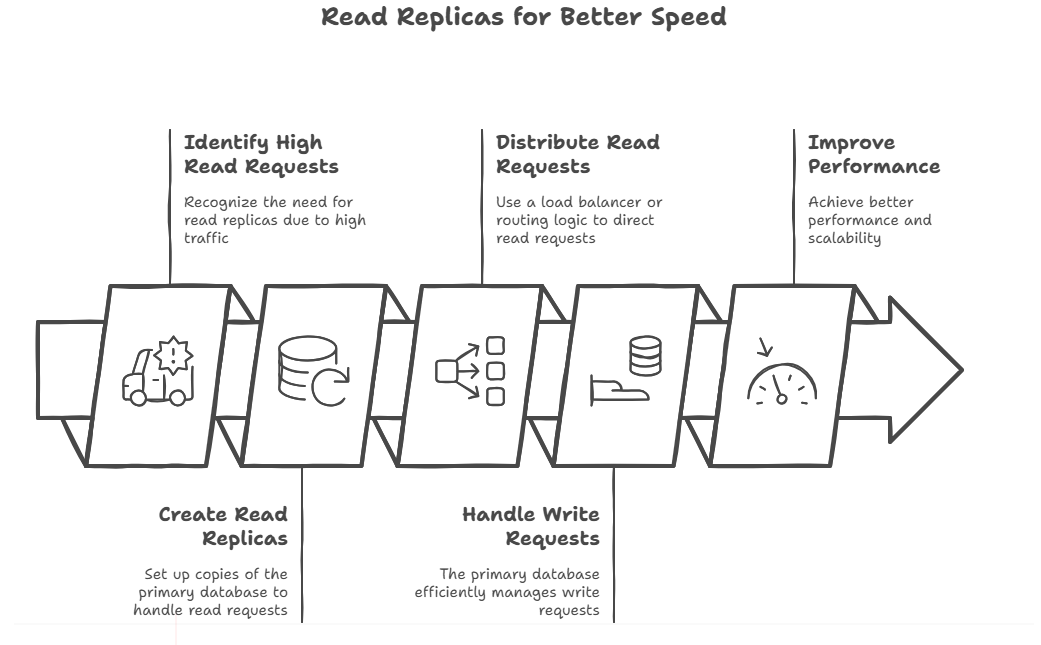
Benefits:
• Improved/better performance.
• Easily scale out.
• Enhanced user experience.
Multi-AZ Deployment for High Availability
This pattern is used in cloud if you want to keep your database running, even if something goes wrong in one location.
In AWS Cloud, if you turn on Multi-AZ for database services like Amazon RDS or Aurora, then a copy of your primary database be created automatically in a different data center (but in same region). If one data center fails (due to any reason), then others keep working.
For example, if you are using RDS MySQL database with Multi-AZ option enabled, then AWS will keep your primary and standby databases in sync. If your primary database goes down (due to any reason, e.g. power outage), then AWS automatically transfers the complete traffic to standby backup database within a few minutes.
This pattern is used when you are running a critical application and downtime is not acceptable.
Banking and healthcare industry applications are good examples of this pattern.
Benefits:
1. High availability.
2. Automatic failover.
3. Strong fault tolerance.
Point-in-Time Recovery and Automatic Backups
Sometimes it is very crucial to save your data from any sudden accident. It might happen that someone can delete your data from the database. Or sometimes a defect in your system could corrupt your entire database.
To protect from such scenarios, AWS Cloud gives you an option to protect your data by taking automatic backups and point-in-time recovery.
If this feature is turned on, then AWS Cloud performs three important tasks:
• It takes backup of your data on daily basis.
• It saves your changes to the database every 5 minutes.
• You can go back to any point within last 35 days.
For example:
Let’s assume that a business application is running 24x7 and suddenly something went wrong at 9:15 AM and it corrupted your data.
With the help of this feature, you can restore your database to just before that time.
In addition to this, you can also test the restored version before deploying a new copy of the database in production environment. In this way, you can recover fast without affecting live users.
You can also consider this feature like an Undo button for your complete database.
This feature is useful for critical applications, accidental data deletion. It also helps in testing and troubleshooting.
Benefits:
1. Data loss is minimum.
2. It helps in precise recovery of your database from sudden accidents.
3. Testing process is simple.
Amazon ElastiCache for Faster Access
If your app receives millions of requests, then it is not a good idea to send each request to the main database. Most of the time, users need to access pages like product information or course detail page. In such type of request are read requests. To handle such read requests, Amazon service ElastiCache saves frequently used data in memory and data is stored with the help of tools like Redis or Memcached.
Example: Suppose there is an e-commerce website which has thousands of product pages and most of the time visitors access the product detail page globally. So, you can store product detail page in ElastiCache. When a user sends a request to access the product detail page:
1. Application checks the ElastiCache.
2. If the requested data is present inside cache, it is returned in a fast way.
3. If not, it fetches from the database and saves the retrieved data to cache for next similar type of read request.
This approach is helpful to reduce the overall traffic load on the primary database and application response time becomes faster.

Benefits:
1. Fast response time.
2. Less load on database.
3. It saves cost and improves.
4. Improves the overall performance of the system.
Monitoring and Failover with CloudWatch and Route 53
For a well-designed application, just having backups and read replicas are not enough. As a good practice, businesses always need to be ready with an alternate plan if something goes wrong.
To handle this, AWS cloud provides two services known as CloudWatch and Route 53.
a. CloudWatch:
This service checks your database for issues like high CPU usage or low memory. You can set alert and it will notify you. It also recommends to take action like adding more resources.
b. Route 53:
This DNS service checks if your database is healthy or not. If not, it transfers all requests to healthy database in another location. You don’t need to do anything manually.
Example:
Suppose your primary database goes down and cannot handle more requests, then Route 53 will redirect all traffic to a backup database stored in another region.
Always keep in mind that you should design your application in such a way that it should be ready to handle anything.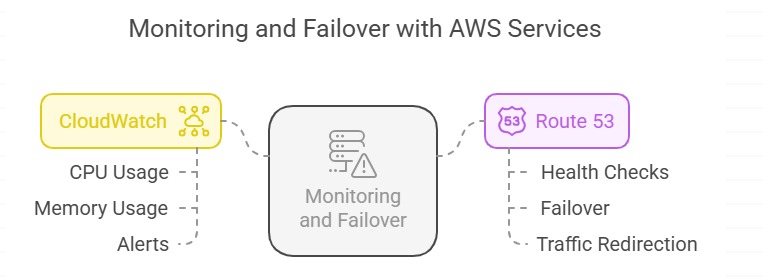
Benefits:
1. Real-time monitoring of resources
2. Automatic switch to backup database
Scaling with Amazon DynamoDB
It is a good choice to support millions of users at a time. In other words, DynamoDB is a NoSQL database that scales automatically. Hence, there is no need to manage servers manually.
Based on your traffic, it can grow or shrink. Clients do not need to worry about their performance or response time of the application.
If you have an application which receives millions of requests per second, then DynamoDB is a good choice.
Example:
Suppose there is a mobile game where users can check live scores and also receive awards at the same time. DynamoDB’s on-demand feature can handle this huge traffic.
If a client has high availability requirements, then one can turn on Global Tables feature, which copies your data in multiple regions.
This option is useful for scenarios like:
1. You have global users.
2. You get unpredictable traffic.
3. You don’t want to manage databases manually.
Must read: AI Career Guide 2025: How to Begin Your Journey in Artificial Intelligence
Case Study: Real World Use of High Availability Pattern
Suppose a client is building a financial analytics platform for thousands of business users.

Requirement: This platform should have 100% uptime.
1. Client decides to host the database on Amazon Aurora MySQL.
2. You start with vertical scaling by selecting a powerful instance.
3. You enable the Multi-AZ option with automatic failover.
4. You add two read replicas in different zones to handle requests related to dashboard and reports.
5. You store most-used financial data in ElastiCache (Redis).
6. You configure daily backups of your data and also enable point-in-time recovery for 35 days.
7. You use CloudWatch service to send alerts.
8. At last, you can use Route 53 for database health check-up and failover.
Note: If there is a sudden spike in traffic, then read replicas (in step 4) and cache (in step 5) can handle read requests.
On the other side, if a defect corrupts your complete data, then you can restore your original data from backup files in few minutes.
In this process, users did not notice any downtime.
With the help of a scalable database and high availability features, it keeps your business always running in a safe way.
Conclusion
Please note that scaling of databases is not only about speed.
Your application should be user-friendly, reliable, and always available.
With the help of the right tools like RDS, Aurora, DynamoDB, ElastiCache, CloudWatch, Route 53, and features like read replicas, Multi-AZ, backups, caching, and monitoring – one can build an application that is robust and stays online 24x7.
Always remember:
Start small, keep monitoring the performance, and grow your business fast with the right AWS services.
User experience depends on how well you have designed your database architecture.

